


Architectural Overview
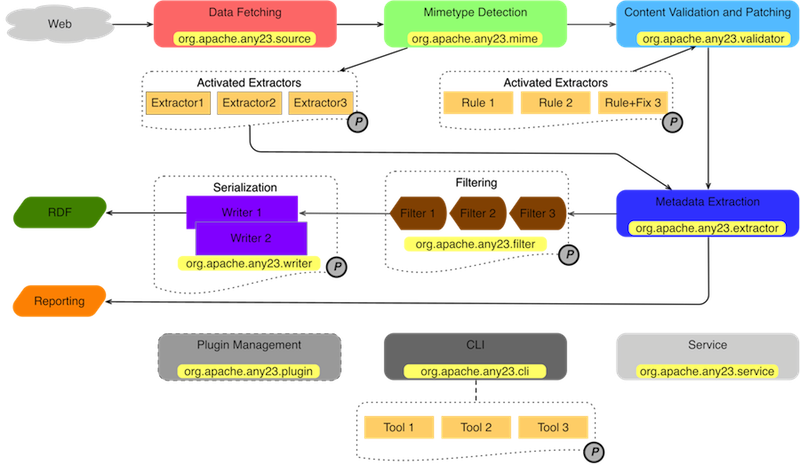
The informal architectural diagram above shows the Any23 logical modules, the main data flow and the code packages implementing such modules.
The first module, Data Fetching, is responsible for retrieving raw data from the Web, its implementation package is org.apache.any23.source. The data collected by Data Fetching is analyzed by the MIMEtype Detection module, implemented in package org.apache.any23. Such module will determine the data encoding and the content MIME type. The identification of the MIME type is used to select a list of activable Extractors for the subsequent metadata extraction.
The next phase is performed by the Content Validation and Patching module (org.apache.any23.validator), and it is required because the most part of data exposed on the Web is affected by minor issues which compromise the correct working of some Extractors. To overcome such problems Any23 introduced a mechanism to detect issues and in most cases to fix them. The detection and fixing is performed using an extensible collection of Rules. Currently the Validation and Patching is applied only on DOM based documents (HTML).
The Metadata Extraction module, implemented within the org.apache.any23.extraction package, applies all the Extractors activated by the analysis phase and generates an RDF statements stream together with an issue report. The statements produced by the Extractors can be filtered to remove spurious, repeated or unwanted triples using the Metadata Filtering module (org.apache.any23.filter).
The last metadata extraction phase consists in the conversion of the filtered statements in an RDF representation format. This can be done by using one of the available RDF writers provided by the Serialization module (org.apache.any23.writer).
The other modules represented at the bottom of the diagram add auxiliary functionalities over the core application. The Plugin Management module (org.apache.ay23.plugin) is responsible for the extension of the platform through the runtime detection and registration of additional components included within the classpath. The Plugin Manager is currently able to detect and register new Extractors, Writers and CLI tools. It is foreseen the plugin support implementation for all the modules marked as (P).
The CLI Tool module (org.apache.any23.cli) allows to run all the available CLI tools through a unified interface.
The Service module (org.apache.any23.service) implements a REST service to use Any23 as a Web service implementing a REST interface.
Developers Guide
This section introduces some Apache Any23 programming fundamentals.
Data Extraction
Explains how to extract RDF data from HTTP resources with Apache Any23.
Data Conversion
Shows how to perform RDF data conversion with Apache Any23.
Validation and Fixing
Demonstrates how to define validation and correction rules for HTML content with Apache Any23.
XPath Extractor
Explains how to write custom scraping rules for extracting RDF data from any HTML content with Apache Any23.
Microformat Extractors
Explains how to write new Microformat extractors with Apache Any23 and also report interesting notes on microformat nesting representation.
Microdata Extractor
Explains how it works the Microdata Extractor embedded in Apache Any23.
CSV Extractor
Explains how it works the CSV Extractor embedded in Apache Any23.